The next failure mode for AI agents will not look like a science-fiction accident. It will look like a normal piece of work moving one step too far before the right person sees it.
That is why the current market language around agent governance is getting sharper. Operators are no longer asking only whether an agent can complete a task. They are asking where the control appears when the task becomes real. A dashboard after the fact feels responsible until the work touches a customer, a ledger, a production system, a legal form, or a team handoff before anyone has reviewed the risky part.
One indexed Reddit discussion about agent accountability put the point in plain operational language: “A review queue after the rush is usually too late.” The example was quick-service restaurant work, but the pattern applies almost everywhere. If the agent flags a questionable decision after the lunch rush, the control did not govern the action. It documented the miss.
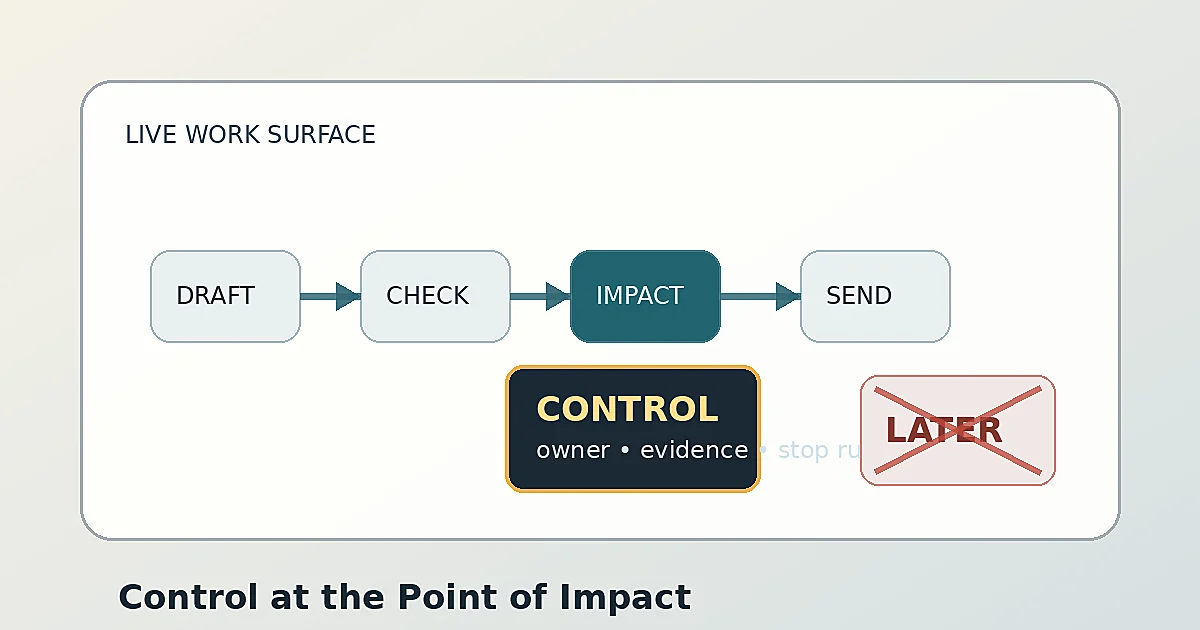
The useful distinction is this: review is not control unless it appears at the decision point.
The review surface is often in the wrong place
Most teams build their first agent oversight layer where it is easiest to build, not where the work actually happens. They add an admin screen. They create a review queue. They send a Slack summary. They export a log. They schedule a weekly audit.
Those are not useless. They can help managers understand volume, quality, cost, and recurring exceptions. But they do not automatically protect the workflow. If the agent can take an action before the review surface is seen, the business has built reporting, not control.
This is the source of a lot of hidden discomfort around AI agents. The prototype looks impressive because the agent can move. It reads the inbox, drafts the reply, updates the CRM, files the ticket, opens the pull request, tags the case, triages the lead, or recommends the refund. The demo celebrates motion. Production has to care about the exact moment that motion becomes consequence.
That moment is different in every workflow. In a restaurant, it may be the kitchen ticket. In finance, it may be the approval before a payment batch. In software, it may be the commit, deployment, or dependency change. In legal aid, it may be the point where general navigation starts sounding like advice. In customer support, it may be the sentence that promises something the company cannot honor.
Agent governance starts by naming that moment.
Adjustable autonomy is the practical unit
The market is already moving away from all-or-nothing autonomy because real work does not fit that binary. Anthropic describes Claude Code autonomy as a range, from approving every action to letting classifiers distinguish safe actions from risky ones automatically. OpenAI’s Codex documentation now talks about workspace controls, RBAC, delegated cloud tasks, local use, and Remote Control permission. KPMG tells CIOs that agent readiness includes decision rights, ownership, monitoring, observability, and “embedding controls directly into service delivery.”
Those are different sources using different language for the same operational reality. The question is not whether the agent is autonomous. The question is which actions require which control level.
A useful agent operating model has an approval gradient. Some actions can be automatic because the blast radius is low and the evidence is clean. Some actions can be drafted but not sent. Some can be recommended but not executed. Some can run only inside a sandbox. Some require a named human before they touch the system of record. Some should stop the agent immediately and surface the case with context.
This is not bureaucracy. It is how a business gives agents room to work without pretending every action carries the same risk.
The mistake is to put the approval gradient beside the workflow instead of inside it. If the person responsible has to leave the work surface, open another system, interpret a vague summary, and decide after the fact, the control will be late or ignored. The control has to appear where the responsible person is already making the next move.
Execution trails are becoming buyer language
Finance and regulated operators are starting to use a phrase that matters: “verifiable execution trails.” That language showed up in indexed public discussion around AI audit trails, and it is going to spread because it names the practical anxiety better than “governance.”
Governance can sound like a policy meeting. Execution trails sound like evidence.
An execution trail answers five questions. What did the agent see? What did it decide? What authority did it use? What did it change? Who owns the next step? If those questions cannot be answered quickly, the agent is not yet part of a trustworthy operation. It may still be useful, but it is not accountable.
This is why logs alone are insufficient. A log may show that something happened. An execution trail shows how work moved through states: drafted, checked, approved, changed, escalated, stopped, retried, or closed. It connects the agent’s output to the business decision that made the output safe enough to use.
That trail should be visible at the control point. The reviewer should not receive an orphaned question like “Approve?” They should see the task state, source evidence, confidence, affected system, proposed action, risk class, and stop condition. Approval without context is just another hidden liability.
The protocol is smaller than the problem
Agent controls do not need to begin as a giant platform. They need to begin as a clear operating protocol.
For each workflow, define the action points where the agent can create consequence. Then assign a control rule to each point. The rule should say what the agent may do automatically, what it may prepare for review, what evidence it must show, who owns the decision, where the decision appears, and what makes the agent stop.
The protocol can be written in plain English before anyone builds software.
For a sales inbox, the agent may classify leads automatically, draft replies automatically, and update a CRM field only when the source is clear. It may not send pricing, promise delivery dates, or mark a deal lost without human approval. The control appears in the salesperson’s normal queue, beside the lead, with the source message and proposed change visible.
For accounts payable, the agent may extract invoice data and match it to a purchase order. It may recommend approval when the match is clean. It may not approve a new vendor, change bank details, or release payment. The control appears in the payment workflow before the batch is created, not in a report afterward.
For software work, the agent may create a branch, modify code, run tests, and open a pull request. It may not merge, deploy, rotate credentials, or change production configuration without a named human. The control appears in the pull request or deployment gate with test results, diff summary, and risk notes attached.
The pattern stays the same. Put the control where the work crosses from suggestion into consequence.
The human mirror matters
Good human teams already do this, even when they do not call it governance. A senior nurse does not review every clinical note at the end of the month and call that control. A chef does not check the tickets after the dinner rush and call that quality management. A controller does not discover bank-detail changes after the payment run and call that approval.
Experienced operators place judgment at the point where judgment matters. They know which decisions can be delegated, which need a second set of eyes, and which require escalation before action. The workflow carries that knowledge because people have learned the consequences of bad timing.
AI agents expose whether that knowledge has actually been built into the system. If the business relies on someone “just knowing” when to pause, ask, check, or escalate, the agent will either move too freely or stop too often. Both outcomes feel like agent failure. Usually, they are protocol failure.
The fix is not to make every agent timid. The fix is to make the authority boundary explicit enough that the agent can move quickly inside safe lanes and stop cleanly at the edge.
How to use this before scaling agents
Before putting an agent into a workflow, run a control-point pass.
First, list the moments where the workflow creates consequence. Ignore the easy parts. Look for the points where a customer sees something, money moves, a record changes, a commitment is made, a legal boundary appears, a production system is touched, or another team inherits work.
Second, decide which of those moments can be automatic, which require review, and which require escalation. Do not make this philosophical. Use blast radius, reversibility, evidence quality, and customer impact.
Third, put the approval inside the work surface. If the action happens in a ticket, put the control in the ticket. If it happens in a pull request, put it in the pull request. If it happens in a payment run, put it before the payment run. If the control lives in a separate dashboard nobody opens during the work, assume it will fail under pressure.
Fourth, require an execution trail for every consequential action. The trail should be short enough to read and complete enough to defend. A human should be able to reconstruct the agent’s path without becoming a forensic analyst.
Finally, measure unresolved work. A control point that catches risk but creates a silent pileup is only half-built. Every stopped, waiting, or escalated task needs an owner and an aging rule. Otherwise the agent has not improved operations. It has moved the bottleneck.
Bottom line
AI agents become trustworthy when their controls live where the work becomes real.
A review queue after the rush is too late. A governance dashboard nobody opens during the decision is too far away. A log without state, owner, authority, and evidence is not enough. The business needs controls embedded at the point of action and execution trails that make agent work inspectable.
That is the operating difference between an agent that can act and an agent that can be trusted.
Sources
- OpenAI Help Center, “Using Codex with your ChatGPT plan,” updated May 2026, https://help.openai.com/en/articles/11369540-using-codex-with-your-chatgpt-plan
- OpenAI Developers, “Codex,” accessed May 25, 2026, https://developers.openai.com/codex
- Anthropic, “Claude Code by Anthropic,” accessed May 25, 2026, https://www.anthropic.com/product/claude-code
- KPMG, “Enterprise AI agents strategy: Where CIOs should deploy—and where to exercise discipline,” accessed May 25, 2026, https://kpmg.com/us/en/articles/2026/enterprise-ai-agents-strategy.html
- Reddit indexed snippets from r/AI_Agents and r/askmanagers surfaced through public search results, accessed May 25, 2026.
Stephen Nickerson.
Built for operators who need AI agents they can test, trust, and improve.